This isn’t going to be a story about artificial intelligence (AI) revolutionising the planning system, solving all our problems in one fell swoop.
It’s a story about applying research, development and real tools to a critical problem: turning mountains of old paper maps, PDFs, and scanned documents into usable data for modern planning systems.
And yes, even after the AI does its part, there’s going to be more work for people to do. Hard, transformative work. But that’s okay. That is where the real value lies.
So what’s the story?
Back in November 2024, we (the Planning Data team in MHCLG’s Digital Planning programme) started chatting with the Incubator for Artificial Intelligence (i.AI) (a team within the Department for Science, Innovation, and Technology that builds AI tools for use across the public sector) about ways AI might help with making the planning system fit for the 21st Century. After a few conversations and some brainstorming, i.AI came back with a list of over 20 potential approaches.
One stood out: the problem of manually converting historical planning documents into structured data. Data that’s needed for modern digital workflows.
Across England, decades of essential planning information – site boundaries, policy zones, conservation areas – are trapped in paper maps, scanned PDFs, and legacy microfiche. This creates a fundamental barrier to modernising our planning system, with councils holding years' worth of valuable records that cannot be easily accessed or used.
To tackle this challenge our two teams have developed an innovative solution called Extract. This AI-powered tool transforms complex geospatial information from static documents into digital, structured formats – significantly faster, more consistently, and at lower cost than traditional manual methods.
And we’re thrilled that this week, at London Tech Week, the Prime Minister Keir Starmer officially launched our tool and committed to rolling it out across England.
Sir Keir Starmer, Prime Minister, speaking at London Tech Week, said:
“With Extract, we’re harnessing the power of AI to help planning officers cut red tape, speed up decisions, and unlock the new homes for hard-working people as part of our Plan for Change.
“It’s a bold step forward in our mission to build 1.5 million more homes and deliver a planning system that’s fit for the 21st century.”
So, we have some exciting work to do, continuing to develop and test Extract in alpha (an initial, internal testing phase) with more local authorities.

Why this matters
Extract is a crucial step towards our vision of a planning system that is fast, data-driven and transparent, truly serving communities across England in the 21st century.
So far, MHCLG’s funding and training has helped 64 councils to publish accessible, reliable data in consistent formats on our Planning Data platform. These datasets will power the next generation of planning software tools like PlanX – that need high-quality data to function effectively – and provide the information we need to train future planning AI tools on.
Extract will make it easier, faster and cheaper for councils to digitise their historic documents and maps, moving key records out of the filing cabinets in the basement and PDFs on file and into the hands of planners, developers, software providers, policy-makers and the public to unlock development and build more homes.
The experiment
i.AI has used their expertise with frontier AI models and the latest machine learning techniques to develop Extract.
Specifically, the team started looking at models like Meta’s Segment Anything Model (SAM) and vision language models (VLMs), which are designed to handle both text and images.
The team set out to achieve a few objectives:
- Extracting textual data: Using large language models (LLMs) to pull out key information – dates, locations, decisions – and format it into datasets following our specifications.
- Image segmentation: Combining VLMs with tools like OpenCV and SAM to trace boundaries drawn on maps, turning them into polygon shapes.
- Georeferencing: Aligning those polygons to real-world coordinates using Ordnance Survey maps and novel AI techniques for finding Ground Control Points automatically.
The approach
Developing AI solutions requires rigorous evaluations. Evaluations enable us to quickly test and learn. Rather than aiming for a single, magical solution, i.AI set clear, measurable objectives from the start. Every line of code and every model tested, was evaluated for accuracy and speed. This ‘evaluation-driven development’ meant we always knew if we were on the right track.
To make this possible, we built a detailed evaluation set of planning documents from around the country. It was varied enough to test the edge cases, but small enough to allow us to iterate quickly. The evaluation set paired old planning documents with their modern data equivalent.
We then broke the core problem down into a two-pronged attack: one for the text, and one for the maps.
Extracting textual data:
First, we tackled the textual information. A planning document is full of vital data, but it’s locked in scanned images of text and unstructured sentences. To solve this, LLMs were used to extract key information – dates, locations, decisions. The model reads the document, understands the context, finds the information, and structures it into Digital Planning's modern data format that a modern computer system can instantly use. By using a trick known as ‘structured outputs’ we can guarantee the LLM will always adhere to the expected format.
We knew what the correct answers should be so we were able to confidently assess if the LLM was capable of finding the correct information.

Image segmentation:
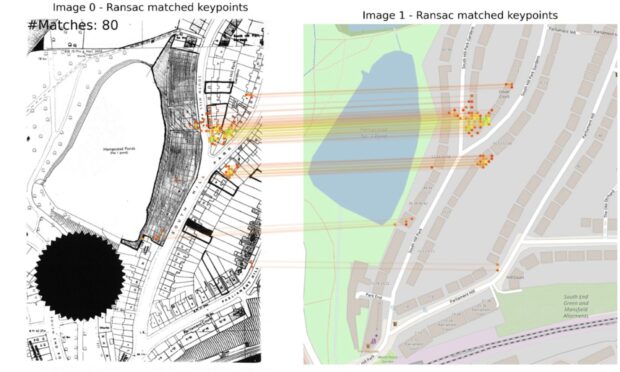
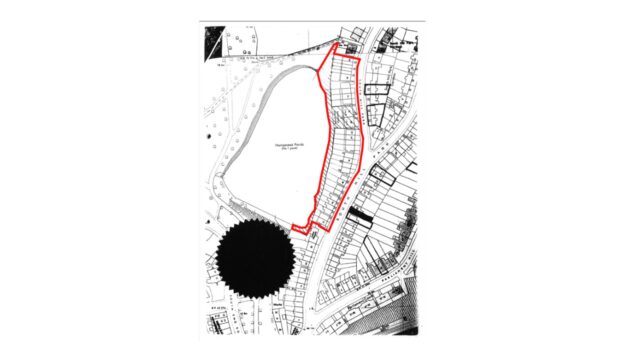
The second, and far harder challenge, was extracting the geospatial data. Standard LLMs are masters of language and words, but they can't natively 'read' a map and produce precise shapes of boundary areas. This is where the novel part of our method comes in. We built a multi-stage pipeline that chains together several specialised AI models – combining VLMs with tools like OpenCV and SAM, to trace boundaries drawn on maps. These are tools that act like highly precise digital scalpels. They can meticulously trace the boundary, creating a clean digital outline known as a polygon.
Placing the shape on a real-world map – georeferencing:
A traced shape is useless until it’s accurately geolocated onto a modern map. This process, called georeferencing, was our biggest hurdle.
Our innovation was to automate the search for Ground Control Points (GCPs). Think of these as digital anchors – identical features like road junctions or building corners that appear on both the old, scanned map and a modern geolocated map. Our system automatically finds these matching points, allowing it to stretch, rotate, and lock the polygon into its precise real-world coordinates.
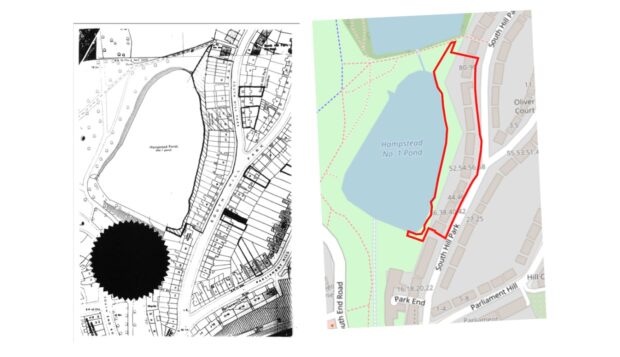
The results
So, after an intense 8-week experiment did our approach work?
The answer is a resounding yes. We successfully proved it’s possible to automatically extract both textual and geospatial data from historical planning documents with remarkable accuracy.
We quickly solved the text extraction task, but the polygon extraction and geospatial location was a stubborn problem that had no prior solutions. After focusing all our efforts on it and extending the experiment by an additional 4-weeks, we had a final breakthrough.
Our final approach, tested against the evaluation set of real-world documents, exceeded our initial success criteria:
- Textual Accuracy: We achieved 100% extraction of all expected text fields.
- Date Accuracy: The system identified dates correctly 94% of the time.
- Shape Accuracy: 90% of the AI-traced boundaries achieved a 0.8 Intersection over Union (IoU), meaning they were a match to the human-drawn ground truth.
- Location Accuracy: This was our biggest breakthrough. After realising a fixed distance (15 meters) wasn’t the best measure, we shifted to a more intelligent, relative metric. Our model placed 82% of boundary centres within 10% of the ground truth shape’s diameter—a precise result.
What this means in practice is a revolution in efficiency. A task that takes a trained officer 1-2 hours of manual work could now be completed by our AI, in under three minutes for about 10p.
This isn’t just an incremental improvement. For a local authority with thousands of historical documents, the impact could be transformative. Whilst we focussed originally on a subset of documents, the approach we’ve invented could be applied to a wide variety of planning documents.
By combining these two pipelines for text and maps, we managed to create a single, seamless workflow to turn a messy, complex planning document into structured, usable geospatial data.
The approach we invented combines the very latest capabilities of AI. It effectively creates a team of AI ‘agents’. These are AI’s that are specialised with instructions (prompts) and given tools needed to do their job. They all work together to extract different information, understanding the context of the entire document and adapting to the wide variety of map and document styles.
What it enables
Extract is more than a tool – it’s a breakthrough that helps unlock one of the most persistent challenges in modernising our planning system. By unlocking decades of trapped data, we’re not only saving time and resources but fundamentally changing what’s possible in planning.
- For councils: Extract saves time and money, freeing up capacity for planners to focus on assessing planning applications rather than data wrangling, and makes it easier to contribute data to national standards.
- For developers and communities: Open, structured data means planning rules are clearer and easier to follow. This supports more viable applications, faster decisions, and fewer delays. Camden Council, for example, saw 60% fewer planning-related calls after publishing clearer data, saving over 21 hours per month.
- For the housing mission: With better data, councils and developers can identify viable sites more easily, support the delivery of more homes - including affordable and social housing – and reduce the uncertainty that currently slows down applications.
- For innovation: Extract lays the groundwork for smarter digital services across planning – from site viability tools and automated policy checks to public platforms that make planning simpler and more transparent for everyone.
- For national priorities: Unlocking data at scale helps build a planning system fit for the 21st century – transparent, predictable, and capable of supporting the delivery of 1.5 million new homes in this Parliament.
Extract is a key part of the digital planning programme’s wider ambition: to turn a system that is manual, fragmented and opaque into one that is fast, modern and built on high-quality data.
What happens next
There is still a lot of work ahead to make Extract into a production ready system. Our incubation period answered the biggest uncertainties and solved the hardest research problems. Now, we need to face the hard engineering problems. Over the coming months we will be making Extract more robust, reliable and scalable so it can be used by local planning authorities.
Our roadmap:
- Complete alpha with iterative improvements
- Launch private and public beta phases in 2025
- Release Extract as a live service for local authorities to use in spring 2026
As we continue to develop Extract from alpha to a fully deployed service, we’re excited to see how this technology will help create a planning system that works well for communities, developers and local authorities alike. We’ll continue to evolve the Planning Data Platform – prioritising data types and formats based on user needs and helping councils maximise their data contributions, to make the system more transparent, efficient and responsive.
And for more information
Watch the Prime Minister’s announcement at London Tech Week
More information about Extract
Extract uses Google DeepMind's Gemini model. Check out Google’s blog post.
Keep up to date with the Digital Planning programme, by following us on LinkedIn and subscribing to our newsletter.



18 comments
Comment by Daf posted on
This is ace. Well done!
So, the text extraction bit.
Am I right in thinking you've defined a content model (structure and organisation of content as data types) and asked the AI to match the PDF content to the content model?
I'm interested in this!
Comment by Gavin Edwards posted on
That’s correct, we use the schemas defined by the Digital Planning platform and a trick called structured outputs to force the AI to adhere to those content models.
This means we can guarantee that the output will always be compliant and follow the same structure.
Comment by Anderw Borg-Fenech posted on
It all sounds extremely positive. It would be good to see a step-by-step comparison of extract doing the same work on a case as a planner to see exactly where the time can be saved. e.g. how the same case is processed by a planner using extract and without extract.
Comment by Gavin Edwards posted on
Thanks! Great points, this is what we’ll be doing in our alpha stage over the coming months. We’re aiming to run detailed comparisons and produce an evaluation report revealing the benefits and weaknesses when used by real planners. We’ll make this evaluation public for all to read.
Comment by Andrew Stumpf posted on
Is there discussion with the devolved administrations too?
I can see that they are likely to have similar issues and not just planning - archaeology and heritage come to mind but also sources of pollution, leaching etc. from heritage industries.
NRW did a lot of work on their LandMap but I assume that was manual work?
Good stuff!
Comment by Jenny Colebourn posted on
Thank you for your interest. We're still in the early stages of developing Extract and at the moment the scope is focused on a few planning document types, where we see great potential, to get the accuracy right. We'll confirm a roadmap when we're further down the track.
Comment by Meg posted on
This is great, but wish it didn't include the dig about 'filing cabinets in basements'. Local authorities have (for a long time) employed records professionals to care for the records in their custody, and indeed do this within appropriate storage conditions. Let's not disregard the labour and generations of care that has ensured the survival of documentation.
Comment by Digital Planning team posted on
Thank you for your feedback. You're absolutely right - local authorities work diligently to preserve important documentation with proper care and appropriate storage. We've heard about the amount some local authorities have and our intention was to highlight the new digital possibilities. We'll be more mindful in our communications in this regard going forward.
Comment by Peter Rich posted on
I was surprised at "15 meters" - please consider.
Comment by James Maxwell posted on
This is absolutely fantastic. Well done team. This type of thinking will help the British state to become more innovative and nimble, exactly what's needed to help us move out of stagnation. Also loving this transparency and openess – even when things don't prove successful – that's how innovation works.
Comment by Andy Mabbett posted on
Great project.
The colour map tiles look like OpenStreetMap. If so, why aren't they attributed?
Comment by Digital Planning team posted on
Thank you for your feedback and for spotting this. You're right - while our actual code only uses Ordnance Survey Map tiles, the visuals we created to help visualise the underlying process do use OpenStreetMaps. We've now added the proper attribution credits
Comment by Susan M. posted on
That's very impressive. Do you plan to publish the approach with more details? I would be interested in particular in the part "combining VLMs with tools like OpenCV and SAM, to trace boundaries drawn on maps", Did you prompt SAM with points, and was any fine-tuning required for SAM or the VLM to get accurate results?
Comment by Incubator for Artificial Intelligence (i.AI) posted on
We plan to open source the code, alongside a technical report at the end of our alpha stage. In our current version we are using a combination of SAM prompts (single points, multiple points, boxes) to extract the boundaries on maps. We are also looking into fine-tuning SAM to optimise performance in future iterations of Extract.
Comment by Graeme Cooke posted on
Great work! Are there any plans to offer an API for back office system providers to feed documents directly into the tool?
Comment by Digital Planning team posted on
Thanks Graeme, that’s an interesting idea! We’ll sound this out with local planning authorities during the alpha phase, but it’s something we’ll probably look at in-depth during the beta phase (which comes later).
We’ll add it to the backlog to explore and validate whether it's a user need. We plan to publish a roadmap, where you’ll be able to see our plans for the future.
Comment by Lynette Young posted on
Is there any plan to include conversion of Microfiche to digital? A number of councils on ODP hold historic records in this "ancient" and inefficient format and converting it is time consuming and costly.
Comment by Digital Planning team posted on
Extract has been developed to automate just the final part of conversion - turning PDF scans into geospatial data.
We recognise there is still significant work involved in getting data onto PDF, and are working with HM Land Registry to understand how we can support councils in this process.